Hypothesis testing allows us to evaluate a hypothesis, or compare two hypotheses. I include it here as part of the theoretical framework necessary for validation of the statistical models offered.
In hypothesis testing, there are two hypotheses.
 is the null hypothesis. This is generally the hypothesis we are trying to disprove. We attempt to mount evidence against the null hypothesis.
is the null hypothesis. This is generally the hypothesis we are trying to disprove. We attempt to mount evidence against the null hypothesis. is the alternative hypothesis. This is the hypothesis we are ready to accept if the null hypothesis is not rejected.
is the alternative hypothesis. This is the hypothesis we are ready to accept if the null hypothesis is not rejected.
Types of Error – There are 2 types of error associated with hypothesis testing.
 is the probability of rejecting given is true.
is the probability of rejecting given is true. is the probability of failing to reject given is false.
is the probability of failing to reject given is false.
- Power of a test is given as
 . It is the probability of rejecting given is false.
. It is the probability of rejecting given is false.
- Power of a test is given as
A  -value, associated with a test statistic, is the largest -level at which we would still fail to reject the null hypothesis, given the data on hand. It is interpreted as the probability of seeing a sample (the data) as extreme or more extreme than what you saw, given (the null hypothesis) is true. We can NOT interpret the p-value as the likelihood that the null hypothesis is true. Data can not serve to prove the null hypothesis is true, data only offers evidence that it is untrue. We evaluate the strength of that evidence using the hypothesis test.
-value, associated with a test statistic, is the largest -level at which we would still fail to reject the null hypothesis, given the data on hand. It is interpreted as the probability of seeing a sample (the data) as extreme or more extreme than what you saw, given (the null hypothesis) is true. We can NOT interpret the p-value as the likelihood that the null hypothesis is true. Data can not serve to prove the null hypothesis is true, data only offers evidence that it is untrue. We evaluate the strength of that evidence using the hypothesis test.
Example: Normal Hypothesis Testing, Known Variance, Unknown Mean
Let us assume that a sample of size  is taken from a population with a known variance
is taken from a population with a known variance  , and unknown mean
, and unknown mean  . We know this population to be normally distributed, so we can model the sample mean using a normal distribution without any further assumptions.
. We know this population to be normally distributed, so we can model the sample mean using a normal distribution without any further assumptions.

Let’s say we have an initial guess as to the population mean, that we’re trying to disprove. We represent that with our null hypothesis. The alternative is given as the alternative hypothesis.
- :

- :

By nature of their definitions, we can’t calculate Power or levels without an actual value for , so I’m not going to here.
The test statistic for the normal distribution,  , is defined as
, is defined as  . is normally distributed with mean 0 and variance 1. In this case, because we’re conducting a two-sided test, we calculate the rejection region of our test as being outside the range
. is normally distributed with mean 0 and variance 1. In this case, because we’re conducting a two-sided test, we calculate the rejection region of our test as being outside the range  . Depending on our intended level of significance, we go to the Z-table to get those values. If we use an level of .05, then that range is approximately (-1.96, 1.96).
. Depending on our intended level of significance, we go to the Z-table to get those values. If we use an level of .05, then that range is approximately (-1.96, 1.96).
So if the calculated from  is greater than 1.96, or less than -1.96, then we reject the null hypothesis.
is greater than 1.96, or less than -1.96, then we reject the null hypothesis.
Example: Normal Hypothesis Testing, Unknown Variance
Let us assume we have a sample of size , taken from a population with an unknown variance , and an unknown mean . We believe this population to be normally distributed, but since we don’t know the variance we can not use the normal model. Thus enters the Student’s T-test.
Because we don’t know the variance, we have to use an estimator of variance. The unbiased estimator of variance is  . We use
. We use  degrees of freedom here because we subtract 1 for calculation of
degrees of freedom here because we subtract 1 for calculation of  .
.
Since we used an estimator of variance, we must use a different test statistic. Enter the  statistic.
statistic.

The  follows a student’s t distribution with degrees of freedom. The distribution itself asymptotically approaches the normal distribution as the degrees of freedom go up. In practice, it’s generally safe for sample sizes larger than 30 to simply use the normal distribution. However, because we’re performing calculations by computer, we can let the computer do the calculations and use the t distribution with however many degrees of freedom we have.
follows a student’s t distribution with degrees of freedom. The distribution itself asymptotically approaches the normal distribution as the degrees of freedom go up. In practice, it’s generally safe for sample sizes larger than 30 to simply use the normal distribution. However, because we’re performing calculations by computer, we can let the computer do the calculations and use the t distribution with however many degrees of freedom we have.
But anyways, we find the appropriate critical value for the given degrees of freedom, and level. If as calculated by  is less than
is less than  or greater than
or greater than  , then we reject the null hypothesis.
, then we reject the null hypothesis.





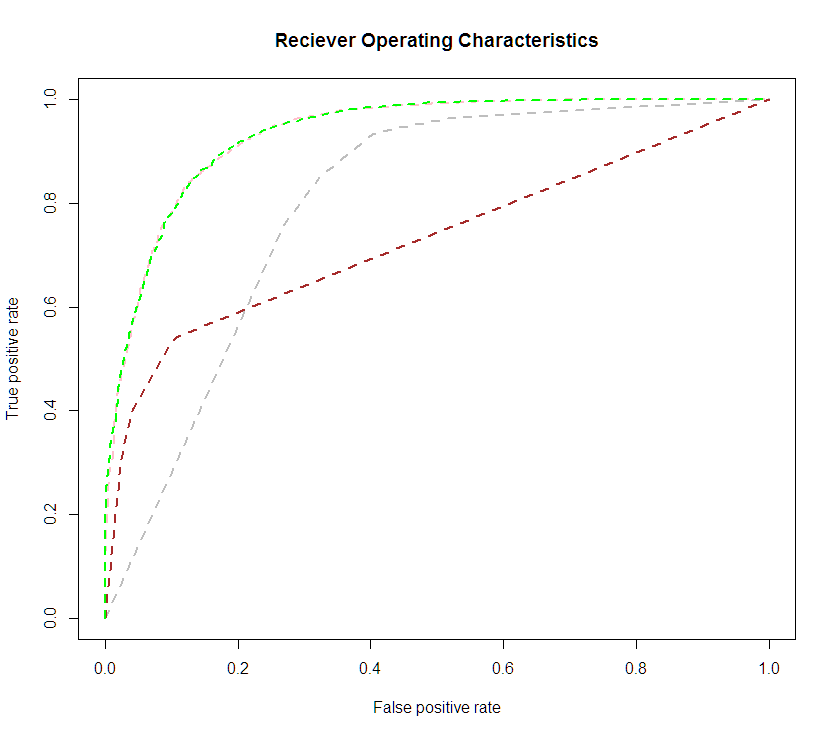
 Specificity on the X axis. The purpose is to observe how the sensitivity and specificity change as you vary the discrimination criteria. Most classification models will put out a value between 0 or 1 that represents the “odds” that that observation is a 1. the discrimination criteria is the cutoff point on that range (0,1) for which you declare that observation to be a 1. As you vary that cutoff point, you generate lines on the ROC curve. Then you pick the best cutoff point. In absence of other criteria for determining the best cutoff point, we will typically use the value that maximizes the lift, or distance between the observed sensitivity, specificity, and the diagonal line, where sensitivity is equal to specificity. This distance gives us a measure of how much better we’re doing than random guess.
Specificity on the X axis. The purpose is to observe how the sensitivity and specificity change as you vary the discrimination criteria. Most classification models will put out a value between 0 or 1 that represents the “odds” that that observation is a 1. the discrimination criteria is the cutoff point on that range (0,1) for which you declare that observation to be a 1. As you vary that cutoff point, you generate lines on the ROC curve. Then you pick the best cutoff point. In absence of other criteria for determining the best cutoff point, we will typically use the value that maximizes the lift, or distance between the observed sensitivity, specificity, and the diagonal line, where sensitivity is equal to specificity. This distance gives us a measure of how much better we’re doing than random guess. (pronounced Lay-tech, the X is supposed to be a capital
(pronounced Lay-tech, the X is supposed to be a capital  ) is a typesetting environment used to generate a professional looking output, and automate some of the more tedious tasks of writing a paper. It is the de-facto standard for writing scientific papers, and it is a good idea to learn it if you intend to release academically. Also, if you’ve been frustrated fiddling with Microsoft’s Equation Editor for writing your papers, LaTeX will alleviate your pain.
) is a typesetting environment used to generate a professional looking output, and automate some of the more tedious tasks of writing a paper. It is the de-facto standard for writing scientific papers, and it is a good idea to learn it if you intend to release academically. Also, if you’ve been frustrated fiddling with Microsoft’s Equation Editor for writing your papers, LaTeX will alleviate your pain. is the vector of dependent variable observations. It is
is the vector of dependent variable observations. It is  is the matrix of dependent variables. It includes a vector of 1’s as the first column to represent the intercept. Its dimensions are
is the matrix of dependent variables. It includes a vector of 1’s as the first column to represent the intercept. Its dimensions are  observations wide. (Note: If we are purposely not including the intercept in the model, then we omit the leading vector of 1’s, and the dimensions of
observations wide. (Note: If we are purposely not including the intercept in the model, then we omit the leading vector of 1’s, and the dimensions of  are
are  .)
.) is the vector of coefficients. Its dimensions are
is the vector of coefficients. Its dimensions are  long, 1 wide. (Also note: If not including the intercept,
long, 1 wide. (Also note: If not including the intercept,  is dropped, and the dimensions of
is dropped, and the dimensions of  .)
.) is the vector of errors.
is the vector of errors.

 . So we want to minimize
. So we want to minimize  .
.
 to yield
to yield

 exists, then we can solve the normal equations, yielding our estimator for
exists, then we can solve the normal equations, yielding our estimator for 
![\begin{align*} \bhat &= [(X'X)^{-1}X']Y\\ E(\bhat) &= [(X'X)^{-1}X']E(Y)\\ &=(X'X)^{-1}(X'X)\beta\\ &=\beta \end{align*}](https://scg.sdsu.edu/wp-content/ql-cache/quicklatex.com-c0b3e8bc6ada67d5b74c74e3da98c22a_l3.svg "Rendered by QuickLaTeX.com")
![\begin{align*} Var(\bhat) &= [(X'X)^{-1}X']Var(Y)[(X'X)^{-1}X']'\\ &= [(X'X)^{-1}X']I\sigma^2[(X'X)^{-1}X']'\\ &= (X'X)^{-1}\sigma^2 \end{align*}](https://scg.sdsu.edu/wp-content/ql-cache/quicklatex.com-9e9221323817950c05e4d56726762e5a_l3.svg "Rendered by QuickLaTeX.com")
 . This will be necessary for estimating the Confidence Interval
. This will be necessary for estimating the Confidence Interval can be defined as
can be defined as
 is the sample standard deviation of the residuals, and
is the sample standard deviation of the residuals, and  is the jj’th element of
is the jj’th element of 
![\begin{align*} \yhat &= X\bhat\\ &= X[(X'X)^{-1}X'Y]\\ &= [X(X'X)^{-1}X']Y\\ &= PY\\ P &= [X(X'X)^{-1}X'] \end{align*}](https://scg.sdsu.edu/wp-content/ql-cache/quicklatex.com-d672416be9be6c59a5401a0d3b58fa0e_l3.svg "Rendered by QuickLaTeX.com")
 is the
is the  th observation of the variable
th observation of the variable  .
. is the
is the  .
. is the mean of the predictor variable
is the mean of the predictor variable  is the mean of the outcome variable
is the mean of the outcome variable  is the predicted value for variable
is the predicted value for variable  is the residual, or distance from the fitted value
is the residual, or distance from the fitted value  and the actual value
and the actual value  is a coefficient, and expresses the linear relationship between
is a coefficient, and expresses the linear relationship between 

 on
on 

 .
.

 , and find the associated
, and find the associated  can be calculated as:
can be calculated as:
 sure the true regression coefficients lie within those bounds.
sure the true regression coefficients lie within those bounds.
 .
.
